The Authorization Failed on the Last Request Please Refresh Your Screen to Login Again
⚡ Appoint UPDATES ⚡
Learn most the touch of Engage technology, including
new capabilities and features, technical issues, and more.
Live Status! 🌡️
Engage is extremely proud of maintaining 99.97% or amend up-time since our inception. Nosotros're likewise radically transparent and sometimes nosotros feel some hiccups. If yous're interested in seeing the up-time of Engage infrastructure, you can view our publicly publishes status at whatsoever time by clicking on the push button below.
Engage DNS Propagation Latency
Over this past weekend (03/25/22-03/27/22) nosotros began a DNS migration project. All our DNS traffic is routed through our CDN Cloudflare. Typically new DNS propagation takes up to 24 hours, but is usually much shorter (4-6 hours). This was scheduled for over the weekend and on off-hours. Withal, we are getting some reports of service accessibility issues due to latency of DNS propagation. The symptom is that api.engage.co, directory.engage.co, and dashboard.engage.co may not exist accessible to some users. Nosotros're not sure why the DNS propagation is taking longer than expected to resolve for some users, but we do wait this to articulate up on its own. Unfortunately this is one of the complications of the style that DNS server modification works: information technology can take fourth dimension to update across the internet. Thank you for your patience.
Appoint Elastic Search Latency
On Mon three/21/2022 the Engage chat service started experiencing latency of Elastic Search. The symptoms were slow login and an bear on to the displaying of chat widgets. We believe this was due to an unanticipated spike in traffic that put a heavy request load on key infrastructure, which subsequently affected the API service. Engineering science spent a couple of hours on Monday night evaluating and resolving the issue. Unfortunately, it reared upwardly again mid-morn on Tues (3/22). It is not down, only it is sluggishly slow to the point it may impact usability. We are again researching the issue and will provide an update soon. UPDATE: As of Tues at 11:53pm PT all Engage organization were working properly. We discovered a previously unknown CPU/memory limit that nosotros were bumping up against. As a outcome, we experienced 3 minutes of downtime on three/20, 48 minutes of downtime on 3/21, and and 48 minutes of downtime on 3/22. However, the latency of our system caused many users issues in logging in, and the chat widget service was sporadic. The new retentivity limits were adapted in one case discovered terminal dark and we fully look all systems to be working well for the foreseeable futurity. Our deepest apologies for this previously undiscovered scaling issue and any impact it caused.
Engage API Service Non-Responsive
On Thursday January thirteen, 2022 at viii:20am PDT the Appoint API service became unresponsive. We are running tests and will either A) restart the API service, or B) spin up a new service. Nosotros suspect this may accept been acquired by updates nosotros pushed last night, but were not previously detected during staging testing. So, it's either curl dorsum or push forward. Nosotros'll accept one or other shortly. Give thanks you for your patience. UPDATE: 8:51 am PDT, we have detected the error. The chat history service (recall of all prior chat conversations) is having a hiccup due to other improvements nosotros implemented. We have reset the service. Simply there may be some continued login latency while we make code updates over the next ii days. We are investing heavily in service improvements. UPDATE: x:02 pm PDT We pushed out all code changes and Engage is moving FAST! The clock speed on response times is faster than ever! We appreciate everyone's patience with united states every bit we worked double-time to get these new service enhancements rolled out. Hopefully your experience is seamless! 😉
Engage Dashboard Login Error
On Tuesday January xi, 2022 at 10:57am PDT some users of Appoint have been unable to login, depending on their Region (AWS Zone). The result is that an attempt to login displays an "error" code. Nosotros are rebooting both of those zones and resetting login access. UPDATE: as of 11:29am PDT logging in should be fully functional across all zone.
Amazon AWS Down at 6:03am PDT
On Tuesday December 7, 2021 at 6:03am PDT Amazon AWS services were experiencing rolling outages impacting the US-East-1 region. We have not detected any reanimation or touch on for Appoint services, but given the fact that we are on AWS and exercise utilise US-East-1 region (among others) we wanted to be proactive. It has impacted many services such every bit Slack, Netflix and others. While we practise utilize Usa-East-1 region, nosotros have load balancing and regional failover. So far, so proficient. We volition provide updates if we detect any impacts.
UPDATE 2:51pm PDT 12/7/21. Unfortunately nosotros did experience some latency and connectivity issues with AWS services in the US-East-ane region from approximately 2:04pm PDT to ii:46pm PDT, only so service levels returned to normal. Our understanding is that a number of services were knocked out up to five hours, so relatively speaking Engage has has less touch that others. That said, we apologize for any issues yous experienced. Information technology does appear that U.s.-East-1 region is dorsum online.
Engage API reset 11/eight/21 at 8:02 CDT. If you are unable to login, delight refresh your browser page https://dasboard.engage.co to login.
Engage API Unresponsive 10/26/21 - 10/27/21
On Tuesday October 26, 2021 at 6:09am PDT the Engage service became unresponsive for some customers. As a result, for users in certain regions information technology become sporadic whether or not they are able to login to the Engage chat dashboard. The symptom was that login attempts would result in the word "error" beingness displayed. Our engineering science team is evaluating this regional access issue and unusually high API request volumes. If you are having whatever issues logging into your business relationship, nosotros do apologize and nosotros are working to make the system responsive for you as soon equally possible. Thank you.
UPDATE: as of 10/27/21 at viii:39am PDT this issue is still impacting some Appoint users. Nosotros are continuing to evaluate the underlying issue causing hallmark pathway errors.
UPDATE: as of 10/27/21 at nine:46am PDT we believe that Engage is experiencing a soft DoS attack. Nosotros take identified unprecedented traffic levels hitting our API. That traffic is originating from People's republic of china, the Russian federation, Mozambique and Malaysia. Historically when we see loftier numbers of API service requests nosotros use our CDN (Content Commitment Network) to issue a JavaScript challenge. Nevertheless, this traffic is sophisticated enough that it is satisfying the challenge and making the requests, which is putting extremely high demands on our infrastructure. We are currently implementing country blocks in the hopes that this stops the demands of this traffic. We can't say it will with certainty, only information technology will take approximately i hour for united states to kickoff seeing any positive impact from adding the land blocks to our firewall. Again, we apologize for any inconvenience here. It'south very unfortunate that foreign bad actors are investing their life energy to disrupt the ordinary period of commerce.
UPDATE as of 10/28/21 at 9:34am PDT the Engage API servers and conversation directory service are experiencing rolling outages and failed web server requests. This is a particularly sophisticated DoS (Denial of Service attack). After originating in China and the Russian Federation, it continued extending to other countries. Over the last 24 hours over lxxx% of all this traffic originated inside of the U.South. (assuming that we're not misidentifying the traffic / IP spoofing). While we have implemented JS challenges and country-level blocking, doing and then for the U.S. would evidently stop utilization of the Engage conversation service. We have been in contact with our CDN equally well as filed a written report with the Cybersecurity & Infrastructure Security Agency - Department of Homeland Security, explaining the economic touch on that this DoS set on is having on the commercial communications of Appoint clients and users. Our engineering team is continuing to do all we can to combat this DoS set on. For reference purposes, hither is a reference of the normal activity level of our service vs. the DoS traffic inflicted upon Engage in the last 48 hours:
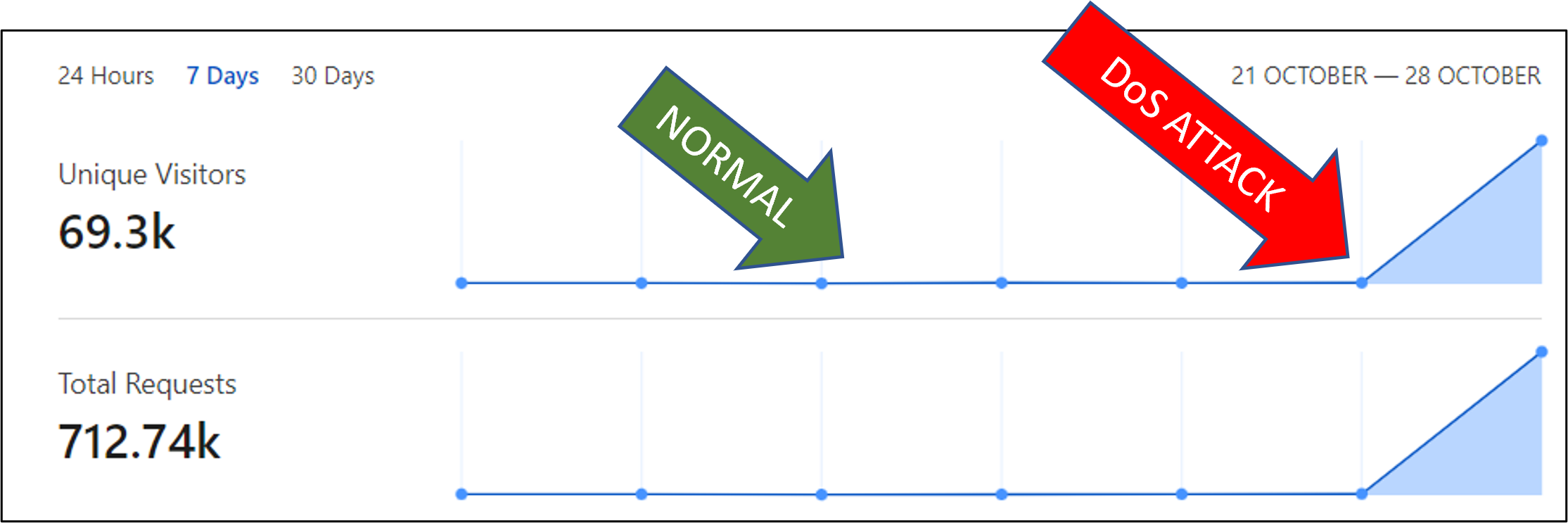
UPDATE as of 11/1/21 at eight:44am PDT the Appoint API servers remain unstable. Our engineering team has been able to reduce by more than half the DoS traffic, so the loads on the Engage API have been such that some users have been able to sneak in and login. But, that has been more about lucky timing that service availability. Nosotros have 2 new proposed applied science solutions that we program to examination and release afterward today. This "deduction past elimination" type of problem-solving is sub-optimal, but unfortunately this DoS traffic is extraordinarily sophisticated and extremely challenging to gainsay without the risk of likewise blocking the service for normal users/clients (we need to avert throwing the baby out with the bath h2o). Thanks again for all the patience and words of encouragement we've received. We know how important the service is to your business organization and we're doing everything in our power to get it back to our historically 99.99%+ availability.
UPDATE as of 9:46pm PDT eleven/i/21 all Engage services are fully accessible. If you are having whatever bug logging in, please refresh your browser and re-login to https://dashboard.engage.co.
Engage Chat Servers Unresponsive Outage nine/seven/21
On Tuesday September 7, 2021 at 7:44am PDT the Appoint conversation servers in the Eastward Coast U.Due south. zone were detected every bit unresponsive. As a result, logging into Engage is blocked until a response from the conversation servers occurs. We are researching load balancing to determine the crusade.
Update: the Eastward Coast zone was restarted at 8:10am PDT and logging in and chat communications should exist working equally expected.
Engage API Outage viii/sixteen/21
On Mon August sixteen, 2021 at half-dozen:44am PDT the Engage API service get unstable. Nosotros are diligently researching this issue. Symptoms include users/customers of the Engage Conversation service are experiencing an upshot where, upon logging into the chat dashboard, they were receiving an "error" message. This effect is impacting users/customers system-wide. We repent for whatsoever inconvenience this is causing and we intend to have you back up and running ASAP.
Update: ten:45am PDT, about users are able to login now, although "previous chats" may non load immediately equally our API service is still running sluggishly. We do expect for it to amend equally the day moves on. The root problem is that there was an unusually high level of traffic from Mainland china and Russian federation in a very short flow of time. Nosotros believe that the request volume caused the instability. We believe this may accept been a lightweight DoS (denial of service) set on. Past default we block traffic from China and the Russian Federation (in addition to several other nations), but a large volume of requests in a short period of time tin can still take a material impact on service delivery. We do apologize for whatever inconvenience this has acquired, but it's another corking reminder of a business organization case for the U.S. to develop its own closed cyberspace: to reduce technical and financial impact from the nefarious, bad actors, and nation-states determined to sow havoc. Unfortunately our openness is something they accept chosen to accept advantage of.
Engage Login Error 8/9/21
On Mon Baronial 9, 2021 at nine:24am PDT users/customers of the Engage Chat service experienced an issue where, upon logging into the chat dashboard, they experienced wearisome load times for the dashboard. In addition, some chat widget were irksome to load. An engineer is researching the network latency causing these slower response speeds
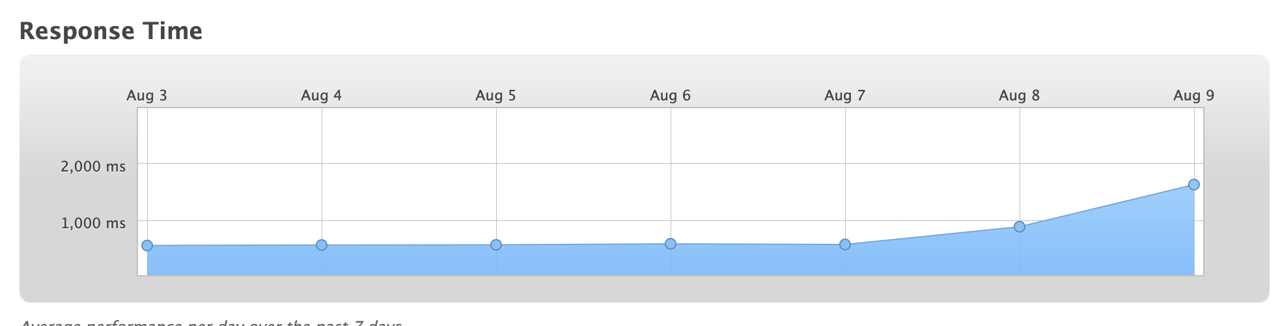
engage is currently experiencing slow response times to api requests
UPDATE: every bit of 11:52pm PDT the response times are back to expected levels with response times under 1,000 milliseconds.
Engage Login Error half dozen/3/21
On Thursday June 3, 2021 at 6:24am PDT users/customers of the Appoint Conversation service experienced an issue where, upon logging into the chat dashboard, they were immediately logged back out of the dashboard application. Our engineers is researching the login persistence outcome at this time.
UPDATE: vi/three/21 vii:53am PDT. We had an ES server on a node that needed to be restarted. All logins are working as expected.
Appoint API Failure 3/9/21
On Tuesday March 3, 2021 at 2:24am PDT users/customers of the Engage Chat service experienced an upshot where, upon logging into the conversation dashboard, they were receiving an "error" message. This issue is impacting users/customers system-wide. Upon further investigation a critical failure of the Appoint API was detected. The Engage engineering squad is working on a rebuild and deploy of the API. Nosotros apologize for this inconvenience and we intend to have you back up and running ASAP.
UPDATE: 3/ix/21 8:52am PDT the Engage API was relaunched. All logins, chat relay and widgets are responsive.
Engage Conversation LOGIN / Automobile-LOGOUT 10/16/20
On Friday Oct 16, 2020 at ix:04am PDT users/customers of the Appoint Chat service experienced an issue where, upon logging into the chat dashboard, they were automatically logged out. This consequence is impacting users/customers organisation-wide.
UPDATE: 10/16/20 10:41am PDT the Engage API was reset and capacity limits were increased. Logging in appears to be working as expected.
Annotation: The IP Geolocation Mapping Service in the Engage Dashboard is current non displaying a map. We're working to update this to a more modernistic and fully featured map. Thank you!
Engage Chat LOGIN LATENCY viii/20/20
On Thursday August 23, 2020 at 7:02am PST some users/customers of the Engage Chat service experienced bug due to load balancing issues with our API service which are due to an unusually large volume of requests to our service. The outcome has been delays in logging, gateway errors on the directory page, and sluggish (slows) load times for the chat dashboard. Our engineering team is aware of these issues and we're working on updating the service. We apologize for any challenges you are experiencing in logging in.
NOTE: If you attempt to log in and get a spinning circle and/or a carmine "error" message, this is symptomatic of the problem with server requests existence unanswered due to the load balance issue.
UPDATE: 8/twenty/xx iii:03pm PST. Proxy routing was updated and all Engage systems and API are again available to all impacted customers. We do apologize to those customers who experienced downtime and/or login bug today. We're still doing research on the spike. It does not appear to be a Denial of Service (DoS) assault, simply we're still not entirely certain about the source. We're going to practise follow-on research and nosotros plan to implement new load balancing measures to help move affected customers onto new systems if/when an result like this occurs in the time to come.
Appoint Chat SERVICE INTERMITTENT UNRESPONSIVE for maintenance 5/23/xix
On Thursday May 23, 2019 at 9:02pm PST the Engage Chat service will exist undergoing maintenance. The typical symptom is that a logged in user is logged out, and some who effort to login are unable (the login appears to just spin while attempting to connect).
We are implementing updates. This is scheduled maintenance between 2019-05-24 04:00:00 UTC and 2019-05-24 06:00:00 UTC. During this time, the following Engage chat will more often than not be unavailable.
Engage API Non-RESPONSIVE
On Mon Jan 28, 2019 at 12:31pm PST the Engage API was determined to be slow or non-responsive. The typical symptom is that, upon a login endeavor, a message comes back maxim "fault" or "dominance failed". This is a symptom of a non-responsive login try. It is very possible your credential are right, but the response is erroneous due to the not-response from the API. We are monitoring the stability of the API service and may do a restart of the service. UPDATE: at 2:11pm PST we did a full restart syncing docs between multiple servers in the cluster ( and ran a total RECOVERING/INITIALIZING sequence). The relaunch was successful. All systems Get! All users should be able to login without effect.
Appoint PRESENCE SERVICE 500 ERROR
On Tues January 15, 2019 at 6:54am PST the Engage presence service experienced a problem causing intermittent problems that are effecting all Engage customers. Users are nonetheless able to login to the dashboard, and the status still works on private chat profile pages (user specific chat URL) just the presence service that instructs buttons and spider web widgets to show people online/offline has become unstable and in many cases is producing a 500 error. In these cases the push or widget will not show the one or more than people who are currently bachelor for conversations and, viewing the underlying reason for the error, it will produce Mistake: 500." A 500 Internal Server Fault is a very general HTTP status code that means something has gone wrong on the spider web site's server but the server. We are currently evaluating the presence service, including several servers, to detect the issue. While this item service has never gone downward before (EVER!), we take learned there is a get-go fourth dimension for everything. We apologize for any inconvenience this has caused, including our customer Syracuse University who trounce #1 ranked Duke in basketball game last night in a stunning overtime victory and who wants to brand sure fans tin can get in touch. UPDATE: at of 10:02am PST on Weds January sixteen, 2019 a set was pushed for this outcome and all presence/condition services were restarted and this appears to have addressed the effect of the presence outage.
Engage API outage nine/5/eighteen
On Weds September five 2018 12:41pm PST the Appoint API was experiencing a massive outage. This is impacted all parts of Engage including login, dashboard, and widgets. This issue was corrected with an API restart at September 5 2018 at 1:05pm PT.
Engage DASHBOARD LOGIN ISSUE
On Tues August 7 2018 iv:41pm PST the subdomain dashboard.engage.co (the login site) was non attainable. As of 7:09am CST on viii/8/2018 dashboard.engage.co was still inaccessible. Ii senior engineers and key architects of Engage are looking into the issue. Under normal circumstances the dashboard page where you lot can login should load. Nevertheless, for certain customers the page does not load and is resulting in a page load request timeout. A reset of the web server occurred, but customers plagued with the page load timeout result were still experiencing the issue. Engage uses a CDN (content delivery network) the sits between our service and customers. The CDN helps provider faster web page load times and more than accessibility to Engage services from different markets. It is presumed that there is a CDN configuration or service effect going on and nosotros're researching this straight with our CND vendor. UPDATE: eight/eight/18 2:02pm PST. A patch was released for the issue. Dashboard should be accessible and login should be immediately available. Please annotation that if you're having trouble accessing dashboard.engage.co that it could be a delay in DNS propagation. If so, please endeavor accessing the site afterward and/or performing a shift>refresh of your browser window pointing to dashboard.engage.co. Give thanks you and over again, our most sincere apologies for those impacted by this most unfortunate issue.
Engage DASHBOARD LOGIN Consequence
On Friday July 6 2018 4:19am PST the login site was not allowing logins to the Appoint dashboard. This was reset at vii:04am PST and login is working equally expected.
Appoint API ISSUE
On Thurs June 14 2018 10:19am PST a disquisitional issue was discovered in the Appoint API. The API has been unstable and certain afflicted customers have experienced bug logging in. They symptom is an "fault" message upon logging in. Nosotros are researching the problem. For those of you having trouble logging in.
We discovered at 12:41am PST a widening and critical issue impacting subdomain pages every bit well, including profile and directory pages. Updates volition be pushed as soon as we have resolution.
UPDATE: at 5:21pm PST a reset of all Appoint infrastructure occurred. We recommend refreshing your browser to avoid any potential cached problems. The problems were caused past retentiveness issues and we're looking into methods to combat/avoid this effect again.
Engage chatlog access error
On Tues Apr 17 2018 6:13am PST a critical issue was discovered in the Appoint dashboard that prevents some users from viewing previous chats afterwards they have logged out and logged back in. This result has been discovered to have effected some users going dorsum as far every bit three weeks (to Mar 28 2018). The symptom is that users accept chats, log out of the dashboard, and then re-login at a later date and recent chats do not brandish in the dashboard and are not discoverable in chat history search. This is an extremely complex result that also appears to be impacting chat forwarding (wherein you forward your chat logs to your electronic mail address of record). This issue is currently in "review" status, just has been noted as an unusually difficult issue as it is affecting some users, but not others. Nosotros are also interacting with a major vendor to amend understand recourse measures. We will detail more data as it comes available. In the interim we ask that, if y'all believe you lot are being impacted past this problem, to consider manually copying your log for back-up purposes. Our nearly sincere amends for any incovenience this is causing any of you impacted. We're very transparent about our flaws and this is one rare effect that we're finding extremely vexing. UPDATE: the problem was worked on and we believe a fix is working across all user accounts. The week of 5/21/18 we also re-checked this and it appears that the ready is holding for all conversation logging and conversation history access through the dashboard.
Engage api ACCESS
On Tues April three 2018 7:14am PST the Engage API was experiencing connectivity problems. The cause of this issue is related to a full enshroud. The primary symptom is that those who are not currently logged in experience an "error" message when attempting to login to the Engage dashboard. Our technology group was been notified of the issue. A restart of the cache was implemented and we believe logging in is working. If you continue to receive an error, delight attempt a browser refresh. We repent for any inconvenience. Thanks.
Engage api & DISK SPACE
On Tues January 2 2018 6:14am PST the Appoint API was experiencing connectivity problems. In add-on, a storm of new year's day user logins resulted in a deejay space limit existence reached on our XMPP server. We cleared logs and restarted all infrastructure and thus as of nine:54am PST it appears all systems are working as expected. We have learned from some users that a browser or computer restart have helped with logging in, which could be related to browser caching. We want to apologize for any inconvenience. Wishing you a happy and successful 2018!
Appoint api downward
On Thurs December 22 2017 iv:14am PST that Appoint API was experiencing connectivity bug. One of the problems caused by this issue is an disability to login from the Engage dashboard; upon login attempt either a crimson "error" or "hallmark failed" bulletin shows on the dashboard login screen and does non allow you to login. Because of this problem users who are not able to login also tin can not connect to our presence (condition) organization and therefore volition non show as "online". Our CTO and a Senior Engineer were alerted to the trouble, error logs were cleared, and the API was reset at 6:57am PST. Engage should be fully functional for y'all as of the reset.
Potential Login bug
On Thurs December fourteen 2017 6:02am PST we were alerted that there accept been regional challenges for some users logging in or staying continued to the Engage dashboard. The symptom is that upon login either a red "error" or "hallmark failed" message shows on the dashboard login screen and does not allow you to login, or the login takes a long fourth dimension and when yous do see the dashboard load the content is slow to display. Our CTO and a Senior Engineer reviewed the issue and successfully corrected the issue at vii:17am PST.
Login bug
There have been regional challenges for some users logging in or staying connected to the Engage dashboard. The symptom is that upon login either a red "error" or "authentication failed" message shows on the dashboard login screen and does not let you to login, or the login takes a long time and when you do see the dashboard load the content is NULL. These issues appear to be continued to a major internet outages. The connection problems, which affected several major ISPs, including Comcast, Verizon, and AT&T, come up only after the one-year anniversary of a DDoS attack on internet-infrastructure company, Dyn, that bedridden the net for a day in 2016. All the same, this week'southward outages are thought to take had a slightly more unremarkable cause: a misconfiguration at Level 3, an net backbone company and enterprise ISP, that underpins other big networks.
Infrastructure Maintenance Detect
One or more of instances of Engage infrastructure in the Eastern U.S. Region are scheduled to be rebooted between Fri, 3 Nov 2017 07:15:00 GMT and Friday, iii Nov 2017 x:00:00 GMT for required system maintenance in guild to deploy important updates. Security and operational excellence are our top priorities, and therefore we occasionally demand to do host maintenance. Each instance will experience a clean reboot and will be unavailable while the updates are applied. This generally takes no more than a few minutes to complete. Each instance will return to normal operation after the reboot, and all case configuration and data will be retained.
Engage performs maintenance regularly to ensure that the service continues uninterrupted for our customers. In virtually cases, maintenance can exist performed without service break. When maintenance cannot exist performed without service interruption, we work hard to keep any affect as brief as possible. Thank you in advance for your patience and agreement.
POTENTIAL Impact detect from Engage
The Engage RESTful API service was experiencing downtime as of 7:53am PST, representing our first meaning service interruption since November of 2016. During this period you may be unable to login to the Engage dashboard, and/or logging in may be slow. Another symptom is that the chat history that automatically populate may non brandish at all, or may be extremely slow to load. Underlying hardware hosting our application in the us-east-1 region is experiencing deposition, and our server has been unreachable. Our engineering squad is researching the issue and we will mail updates hither every bit they get available. Give thanks you and apologies for any inconvenience.
UPDATE 8:22am PST Engage relies on Amazon AWS/EC2 services in the delivery of Engage. Amazon has a major server/hardware example failure. Nosotros are looking to create and motion to a new example.
UPDATE 10:21am PST It appears that this server/hardware example failure is catastrophic. We are copying the case, and are rebuilding the instance on completely new hardware. This process may take up to four hours. In the acting period yous may have delays in logging in, you may not be able to login at all, certain data and analytics may non be bachelor, directory services may non update promptly, and some or all site widgets (chat call-to-action elements) may not load on your chief or tertiary-party websites. Over again, we apologize for this unforeseen outcome experienced past our vendor Amazon AWS.
UPDATE 12:32am PST Multiple engineers at Engage are working at breakneck speed to create new instances of the failed servers. In that location were several challenging dependencies and inter-dependencies in moving to a new instance and this piece of work is in-progress. We hope to relaunch the parts of Engage impacted by the failed servers in the next i-2 hours. Information technology's all-hands-on-deck and thank you for your patience every bit nosotros work through this boggling issue.
UPDATE 3:47pm PST Well, that'due south been fun. We did get the work done. Chat widgets are loading, visitor directories are working, the chat profile pages are loading, chat is working. Even so, nosotros're notwithstanding noticing some pocket-size impact bug, especially in the chat dashboard.
UPDATE: vii:05pm PST Everything is up and running, just nosotros're still seeing some "connection problems" in the conversation dashboard relating to "contempo conversations," "chat history," and "stats." The recent conversations and any prior chat searchers are showing as empty (null) in some instances, and the stats reporting volition sit and spin if you endeavour to search a date range or keyword search. Nosotros'll continue working through this problems. Thanks again for your patience as we work through this major hardware failure at Amazon.
UPDATE: 6:03am PST. While it appears the vast bulk of users are able to successfully log in to the conversation dashboard, a few users continue to be impacted. The following issues continue to be reported: 1) unable to login - it just 'sits and spins,' ii) the dashboard does not populate with my recent conversations, three) the dashboard loads like normal but if I click on a contempo conversation it sits and spins, 4) If I attempt to look up chat history or stats information technology does non populate with data and/or sits and spins. Nosotros are yet working to establish better service connectivity throughout the network. We have rebooted all Engage services and taken a number of steps. Appoint besides lives backside a global CDN (content deliver network) and we've confirmed that what'due south working is loading fast. For those of you lot who were impacted yesterday nosotros apologize. For those who proceed to experience admission issues, please know that we'll go on working to make sure we deliver the incredible service and uptime that we're known for. Give thanks yous!
UPDATE: ix:55am PST We have completely reconfigured our servers on the due east coast node where Amazon AWS experienced the major hardware failure. To the best of our cognition, all chat, dashboard, widgets, chat history and stats are functional. The only outcome nosotros are even so seeing is the connection to browser preview. Our heroic engineering squad who have been working for 24 hours to rebuild instances are working on the browser preview rebuild, then they program to get some well-deserved sleep. If you continue to have problems, please first try shift>refresh in your browser. If things are still not working for you lot, delight e-mail u.s.a. at back up. Thank you lot!
POTENTIAL Impact detect from Engage
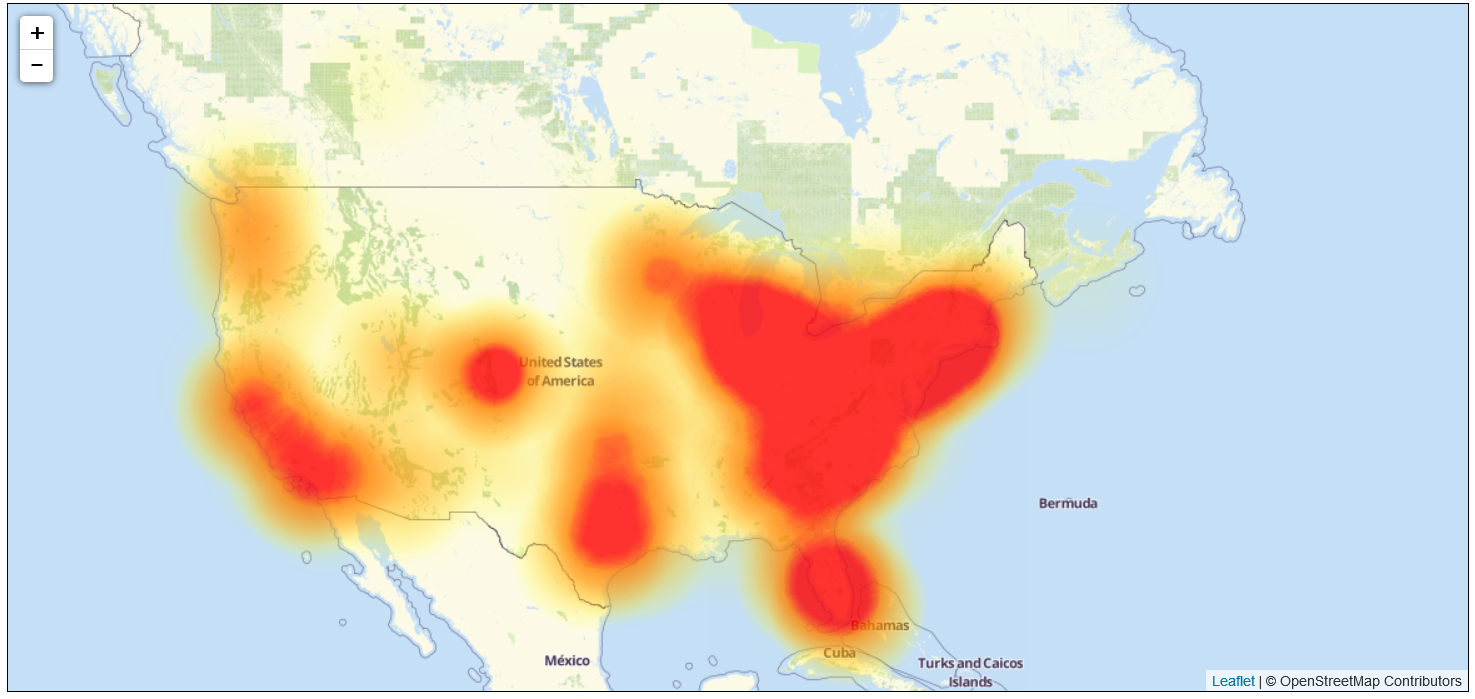
Level iii is one of the largest networks in the U.S. and they are having major outage issues today. As a backbone to U.S. Cyberspace infrastructure many ISPs rely on data transmission on Level 3. The current problems they are experiencing could impact your use of Engage. The status of your users may not exist transmitted, which could result in "error" issues in logging in as well as condition non updating in widgets. Appoint infrastructure is upward, but parts of the Net are being impacted which would cause unusual behavior that could be experienced by some Engage clients. Here is a map of the Level three outage surface area. Engage was non impacted by the last major outage on x/21/16 and nosotros are not seeing any impacts today, simply if your Internet access provider uses Level three as a data carrier, that could explicate the issues. Also, we practice not know for certain if this is another DoS assail similar to what occurred on 10/21/16, or if this is merely isolated to simply Level 3.
A special notice from Appoint
What is believeD to be a serial of unprecedented DoS attacks has caused major impacts across the Internet today. Major websites have been impacted at different points, and reports from the Eastward Coast U.Southward. said at times one-half the Internet went dark. It has been reported that the U.S. Government is looking at this as a criminal human action.
We wanted to update you about Engage. Our website appoint.co has been impacted at several points and some visitors, especially those on the east coast, have not been able to access our site, or parts of our site.
Notwithstanding, none of our underlying services accept been impacted. The conversation dashboard has been up continuously and all widget and chat API services remain at 100% uptime. You lot can e'er view publicly the condition of Appoint infrastructure by visiting: http://stats.pingdom.com/7axuogji186z
Engage employs an extremely high level of security around our platform, and we support the uptime of our platform with distributed infrastructure across a global content delivery network. While we fully expect our service to remain attainable to customers, we are continuing to monitor this situation closely.
Appoint Mistake
-
On Sunday, July 3rd we were alerted past a customer to an issue where they manually logged out of Appoint, shut their computer down, and received incoming chats over the evening. The symptoms were that when logging in the side by side twenty-four hour period being surprised to encounter that incoming chats had occurred over the evening, that the timed-out response did not piece of work, and that the customer contact info and customer information console were non populating with client data. We had not seen this issue previously and all initial tests on our end were unable to reproduce the consequence (though we could observe the behavior in that user's account). The issue seemed to expand to several other users on seven.five.16 (for unknown reasons). As a result, nosotros went all-hands-on-deck with all available engineering resource beingness applied towards addressing the issue. What we suspect right at present is that this issue is being caused by our dashboard infrastructure correctly seeing the user has changed their status to offline, that data is existence reported to our status server, only the status server is non updating the status to "release" the users status to "offline". A number of new test functions have been written to observe the behavior and a solution to the problem is beingness worked through. This trouble had not been previously observed and so its occurrence and persistence have been quite perplexing, but we're optimistic nosotros'll address the issue promptly. If you lot believe y'all have been affected with this effect (most users have not been), please email the states at howdy@engage.co so we can monitor your business relationship. Thank yous. On 7.7.16 this problem continued to be "in-process" with a set. The engineers adult an alternative method to detect and confirm condition between the dashboard and the status servers. A solution is currently in QA testing. An unscheduled maintenance window will occur subsequently hours to reboot 1 or more servers and a software patch will be applied. To those afflicted, give thanks y'all for your patience. Many of you accept taken time to help provide us more information and a fix wouldn't be possible without your cooperation, and so thank you! On 7.8.xvi a server reboot occurred, and a software patch was applied. Nosotros applied a new condition check methodology which allows Engage to cheque both the dashboard AND status servers for availability. For those who are Not double-confirmed as available for chat, you volition be default timed-out in 90-120 seconds. We believe with this gear up the issue has been resolved. If you continue to remain in an "online" status and don't believe yous should exist, please login to Engage, then logout. This volition reset your status and going forward we will double-check your true availability.
Appoint Error
-
On Thursday May 30th we were alerted by a client nearly cleaved chat sessions occurring on an Android device. Engineering institute the effect with Android. Chrome on android was recently updated, and the code that creates the desktop notifications was recognizing the Notification API on mobile, only when it tried to create the notification it failed and blocked incoming messages from beingness candy. As a result, it was possible for an amanuensis in dashboard to not run into messages coming in from a customer, or the ability for the client to see incoming letters. The fix was tested and deployed on half-dozen.1.16. In addition, engineering has added boosted checks designed to keep this from happening in the future.
Appoint Error
-
At approximately 10:45am PDT on May 23rd, 2016 an updated version of Engage was pushed out that included new lawmaking that deployed to a single chat server and not the entire infrastructure, as intended. As a outcome, information technology was possible that for some users incoming chats were immediately disconnected and that actual and visible amanuensis status could non be uniform. A cardinal symptom of this upshot was that a conversation agent would be logged out of the dashboard, requiring them to login once more. A fix was released at approximately 11:57am PDT. Steps have been taken to forestall this in the future and nosotros repent for any inconvenience this may have caused. Rest assured this was not infrastructure reanimation, merely rather a software release issue.
Appoint Dashboard Changes pushed
-
Administrators tin can now control (limit) the number of agents who appear in the widget. In some instances (especially where you accept more than than 30 agents "online" simultaneously) the number of available agents could be overwhelming to visitors. With this new setting you can limit the visible agents to a number (limit) you determine, such equally fifteen agents.
Appoint Dashboard Changes pushed
-
Administrators tin at present disable the widget on your website with a single click. This feature was designed so that when installing Engage and getting team members (users) onboarded the widget won't load. Once you're ready for showtime, you can click it and the widget volition be live. Now yous tin can install the widget code correct away, simply activate the widget when it makes sense for you.
Engage Dashboard Changes pushed
-
Administrators can at present change your team members status between "active" and "inactive" and also delete users. The inactive condition means that the user is finer hidden from displaying in widgets. This is a useful tool if an employee is gone on vacation or leave, or if they use Appoint but are not part of the customer-facing set up of squad members yous wish to display (such as IT people, marketing people, or admins). To alter a user status: one) login to the admin dashboard, ii) click on "edit account" and then click on "team" and so choose the user and click on "status" where you'll be able to toggle between "active" and "inactive".
Appoint Dashboard Changes pushed
-
Administrators can now change your company directory domain name. When the domain has been changed, information technology is updated at the sub-directory construction in the URL. In addition, this change is automatically synced with the Appoint API and updates all widgets and pointers without any required modifications.
-
New reset countersign function.
Engage Dashboard Changes pushed
-
From the Engage dashboard you can now edit your profile
-
The Engage dashboard design and layout received modest changes
-
The message dialogue window has letters of alternating colors
-
Account admins can now edit user profiles
-
Account admins tin at present modify user passwords
-
Account admins can now edit their visitor profile
-
Account admins can at present build unlimited widgets
-
Users and admins can now add photos and logos
Features, Capabilities & Improvements in Development
-
Syndication code Browser Preview Tracking which allows the dashboard to display whatever third-party site where you lot are syndicated to as a referrer source for incoming Engagements
-
Color palette for widgets
-
Make "end chat" and "email transcript" more than obvious in the dashboard
-
Ability for admins to add together categories
-
Power for admins to delete/suspend
-
Advanced statistics / analytics
-
WebRTC updates
-
Existent-fourth dimension B2B/B2C intelligence (Extensions Console)
-
Metadata and Schema
-
Conversation bots and chat automation
-
Pre-canned messages (aka operator scripting)
-
In-dialogue preview of shared URLs
-
Design updates to HTML5 Profile page, including new "End Chat" push button
-
Adding "online" menu pick to HTML5 Company Directory pages
-
Flag to proactively show the same agent previously interacted with based on a tracking cookie
-
Android / Google Play app, with push notifications
-
Apple / iPhone app, with button notifications
-
In-dialogue file/asset sharing
-
More CRM integrations planned, including SugarCRM, Highrise, Insightly, Solve, PipelineDeals, SuiteCRM, vTiger, Zoho, baseCRM, Netsuite, Nimble, SAP and Infusionsoft
-
Simplifying access to existing CRM integrations including Salesforce and Microsoft Dynamics
-
Adding an "SMS" selection for sending asynchronous client communications from the dashboard directly to the customers mobile phone
Source: https://www.engage.co/updates
0 Response to "The Authorization Failed on the Last Request Please Refresh Your Screen to Login Again"
Post a Comment